A1 |
|
A2 |
|
B1 |
|
B2 |
|
C1 |
|


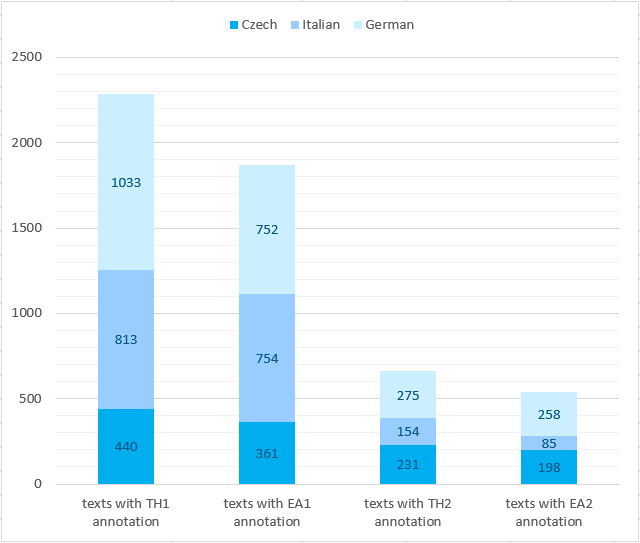
The MERLIN corpus contains 2,286 texts for learners of Italian, German and Czech that were taken from written examinations of acknowledged test institutions. The exams aim to test knowledge across the levels A1-C1 of the Common European Framework of Reference (CEFR).
The corpus comprises written prodcutions from standardized high-quality language tests from telc Frankfurt (for German and Italian) and the Test centre of the Institute of Language and Preparatory Studies (ÚJOP) of the Charles University in Prague (for Czech).
The tasks are systematically related to the Common European Framework of Reference for Languages (CEFR). They were in use until 2013 and are now freely available on this platform.
To ensure an immediate relation to the CEFR, specially trained testers re-rated all exam texts using the MERLIN MERLIN rating grid that was developed within the project.
The reliability of the ratings was subjected to rigorous statistical verification procedures to correct rating tendencies (e.g. leniency/harshness). As a result, a reliable rating profile has been created for each text in the corpus. The profile reflects both a general holistic overall level and the individual rating criteria detailed below:
The page MERLIN for research goes into more detail about the procedure of the re-ratings.
In the following, a comprehensive overview and detailed description of all test tasks which form the basis of the written test productions – the MERLIN texts – is provided. The linked PDF documents contain detailed information about the tasks, a brief description of the test parameters, and the specific characteristics of the intended text, e.g. regarding topic, register, domain.
Hint: In square brackets are the short names of the tasks as you find them in the file name of the MERLIN texts.
 German
GermanA1 |
|
A2 |
|
B1 |
|
B2 |
|
C1 |
|
ItalianA1 |
|
A2 |
|
B1 |
|
B2 |
|
Czech A2 |
|
B1 |
|
B2 |
|
General notes on task descriptionEach text in the corpus is described with the following metadata. These details can be found in the header of individual text files.
For a comprehensive overview of the texts and the metadata associated with them, you can refer to the table ![]() metadata_ratings_indicators.cvs. It also covers, for each corpus text, numerous indicators targeting L2 features, as well as lexical, morphological, and syntactic complexity measures (for the German corpus).
metadata_ratings_indicators.cvs. It also covers, for each corpus text, numerous indicators targeting L2 features, as well as lexical, morphological, and syntactic complexity measures (for the German corpus).
The following charts show the total number of texts at a given CEFR level and the amount of the annotations. The overviews also allow for a comparison of test level and actually rated level.
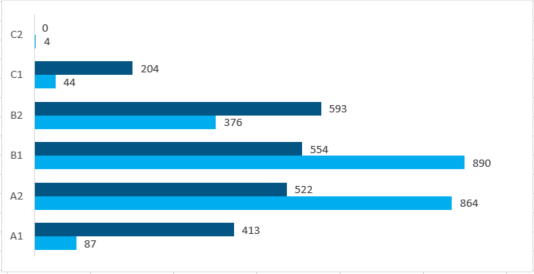
![]() Number of texts per test level (total number of texts in the corpus: 2286)
Number of texts per test level (total number of texts in the corpus: 2286)
![]() Number of text per level assigned in the re-rating (total: 2265)
Number of text per level assigned in the re-rating (total: 2265)
Number of texts per CEFR level an language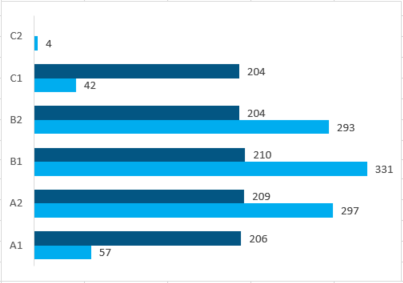
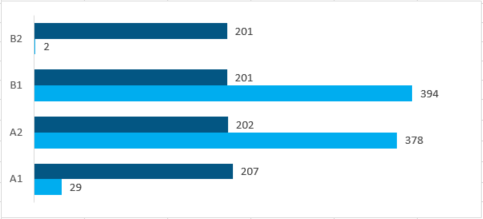
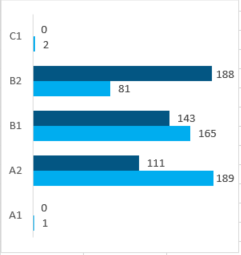
Number of texts per annotation layer